FLAM5 Segment Store
The Segment Store data format is the foundation for storing FLAM5 archives. It is designed to efficiently manage and store archived data in a flexible and scalable manner. All archived data is divided into segments, which are managed through versioned indices. This approach ensures that data can be easily accessed, modified, and maintained over time.
The Segment Store supports two distinct storage formats to cater to different storage needs and environments:
- File Format
- This format is intended for storing the entire archive in a single, sequential file. It is ideal for scenarios where a consolidated file is preferred for ease of management and transfer.
- Object Format
- This format is designed for storing the archive in multiple smaller objects. These objects can be stored locally in a folder-based structure or in cloud-based storage. The object format provides greater flexibility and scalability, especially for cloud storage solutions.
In the Segment Store, all data is stored in segments. These segments are managed via versioned indices, allowing for efficient tracking and retrieval of data across different versions. Each version of the archive maintains its own index, which lists all the segments and their respective metadata. When segments are deleted, they remain accessible through older versions until all older versions referencing them are deleted. This versioning system ensures that changes to the data can be tracked over time, and previous versions can be accessed as needed.
The Segment Store is particularly useful for applications that require robust data archiving and version control. Its ability to manage data in segments and support multiple storage formats makes it a versatile solution for both local and cloud-based storage environments.
The following sections describe both Segment Store formats.
File Format
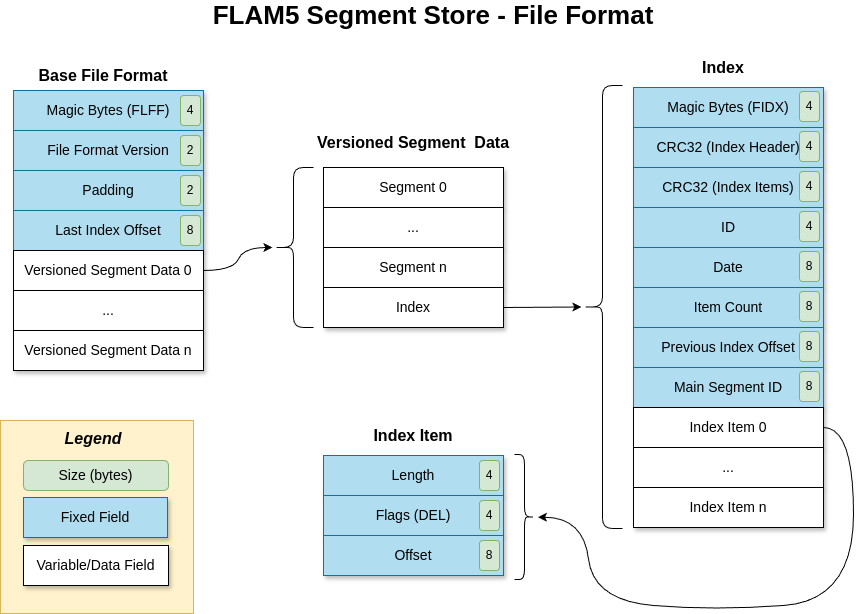
The segment store file format is designed to manage and store data efficiently across multiple versions. Each file contains one or more versions of data, with the data organized into blocks called segments. These segments are managed through versioned indices, allowing for multiple versions to be stored within a single file. This structure enables segments to be added or deleted between versions, providing flexibility in data management. Importantly, even if segments are deleted in newer versions, they can still be accessed through older versions until all versions referencing those segments are deleted.
Each version of the data has its own index, which contains a list of items describing the segments. These items include details such as the length of the segment, a delete flag, and the offset of the segment within the file. The index itself is structured with specific metadata: magic bytes to identify the file format, CRC32 checksums for integrity verification, a unique ID, creation date, segment count, and the offset of the index of the previous version. Additionally, the index includes the main segment ID, which helps in identifying the primary segment for that version.
The file header is a crucial part of the segment store file format. It includes magic bytes to identify the file format, the file format version, and the file offset of the latest segment index. This header ensures that the file can be correctly interpreted and accessed. The index items within each version's index provide detailed information about each segment, including the data length, flags (currently only a delete flag), and the start offset of the segment data within the file. This detailed indexing allows for efficient data retrieval and management across different versions.
Object Format
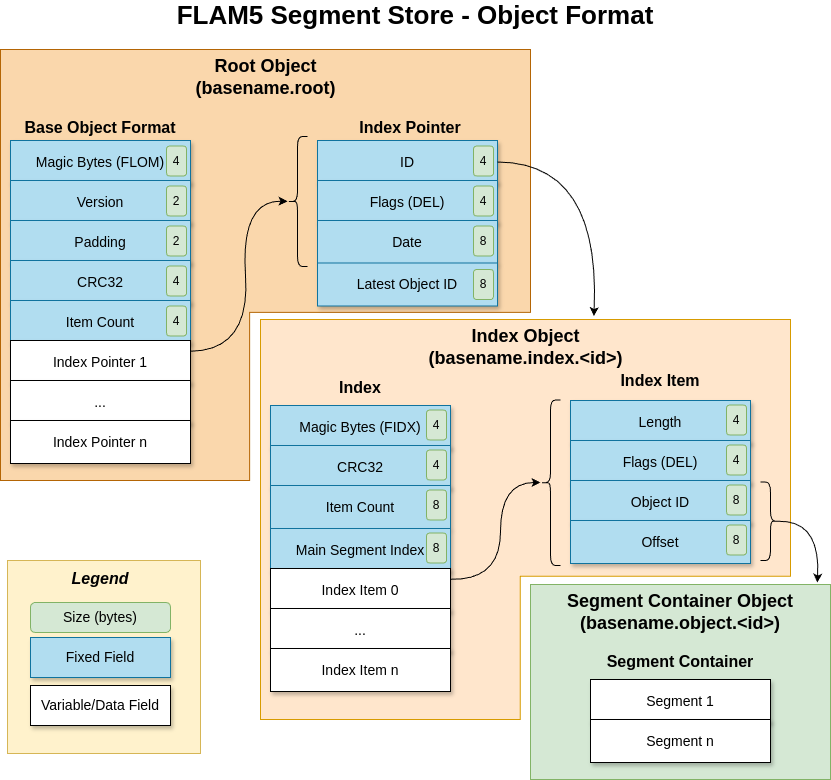
The segment store object format is a versatile and efficient method for managing storage of versioned archives as multiple data objects. It utilizes an abstract storage backend, allowing data objects to be stored either as a folder structure or remotely in the cloud. This flexibility ensures that the format can adapt to various storage needs and environments. The format is designed to store one or more versions of data, with segments managed in versioned indices.
The format defines three types of objects: root objects, index objects, and segment container objects. The root object serves as the entry point, containing pointers to all versioned indices. It includes essential metadata such as magic bytes, format version, CRC32, the number of index pointers, and a list of index pointers. Each index pointer has an ID, delete flag, creation date, and the highest object ID in use. This structure ensures efficient navigation and management of different data versions.
Index objects represent individual versions of data and contain a list of all data segments along with a pointer to the segment container object that stores the segment data. Each index object includes magic bytes, CRC32, segment count, main segment ID, and a list of segments. Each segment entry specifies its length, delete flag, object ID of the segment container, and offset within the container object.
Segment container objects are concatenations of one or more segments, referenced by the index objects. By aggregating multiple segments into segment containers, the format reduces access time, especially when using cloud storage. This design optimizes performance and ensures that data can be accessed quickly and efficiently, regardless of the storage backend.
The format diagram above illustrates the overall structure and relationships between these objects, providing a clear visual representation of the object storage format.